

DriveLM是一个基于语言的驱动项目,它包含一个数据集和一个模型。通过DriveLM,我们介绍了自动驾驶(AD)中大型语言模型的推理能力,以做出决策并确保可解释的规划。
在DriveLM的数据集中,将人工书写的推理逻辑作为连接,促进感知、预测和规划(P3)。在模型中,我们提出了一个具有思维图能力的AD视觉语言模型,以产生更好的规划结果。目前,数据集的演示已经发布,完整的数据集和模型将在未来发布。
项目链接:https://github.com/OpenDriveLab/DriveLM
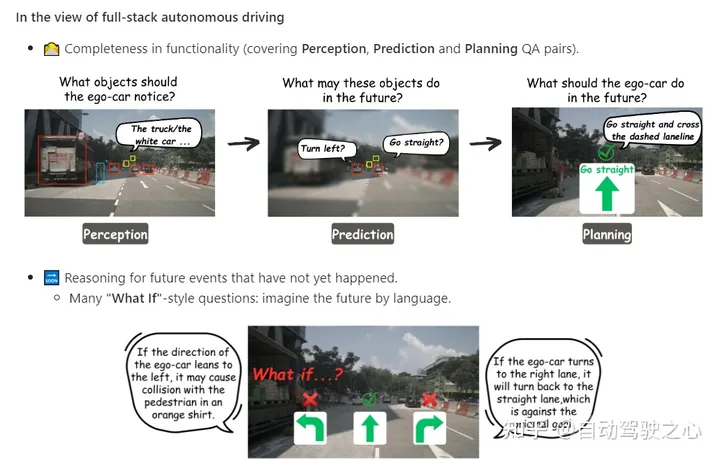

What is Graph-of-Thoughts in AD?
数据集最令人兴奋的方面是,P3中的问答(QA)以图形风格的结构连接,QA对作为每个节点,对象的关系作为边。
与纯语言的思维树或思维图相比,我们更倾向于多模态。在AD域中这样做的原因是,从原始传感器输入到最终控制动作,每个阶段都定义了AD任务。
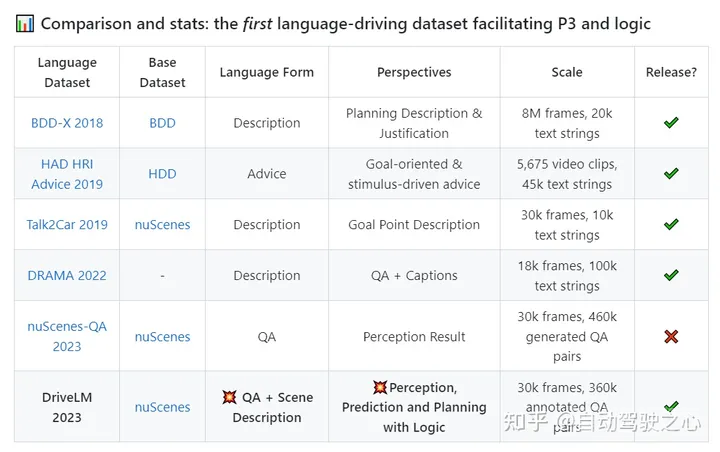
DriveLM数据集中包含什么?
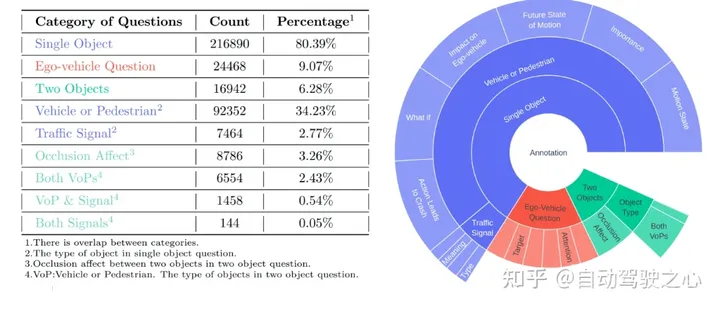
基于主流的nuScenes数据集构建我们的数据集。DriveLM最核心的元素是基于帧的P3 QA。感知问题需要模型识别场景中的对象。预测问题要求模型预测场景中重要对象的未来状态。规划问题促使模型给出合理的规划行动,避免危险的行动。
标定过程如何?
关键帧选择。给定一个剪辑中的所有帧,注释器将选择需要注释的关键帧。标准是,这些框架应该涉及自车运动状态的变化(变道、突然停车、停车后启动等)。
关键对象选择。给定关键帧,注释器需要拾取周围六个图像中的关键对象。标准是这些物体应该能够影响自车(交通信号灯、过街行人、其他车辆)
问答注释。给定这些关键对象,我们会自动生成关于感知、预测和规划的单个或多个对象的问题。更多细节可以在我们的演示数据中找到。




还没有评论,来说两句吧...